Continuing Efforts to Improve the Reproducibility of Research at the Journal of Research in Personality
Richard Lucas
Michigan State University

Anyone who has been paying attention knows that over the past few years, the field of psychology has been struggling with concerns about how replicable the research findings in our journals really are. These concerns stem partly from a few high profile cases of clearly problematic research, but also from more systematic examinations of the typical practices used in psychological research and in scientific research more broadly. Studies are very frequently underpowered, direct replications are rarely conducted, and there are concerns that the "conceptual replications" on which the field often relies (studies that are hardly ever pre-registered) allow for considerable analytic flexibility that inflates the rate of false positives. When these factors are considered in the context of incentive structures that primarily reward new discoveries over evidence that a finding is robust, there is clear cause for concern. Furthermore, fears about the replicability of published results appear to be confirmed by recent systematic attempts to reproduce several findings from the field.
In response to these developments, there has been vigorous debate-debate that has sometime been quite contentious—about the extent of the problems and about what to do to improve the field. Editors and publication committees have struggled to determine whether policy changes are needed, which changes will do the most good, and how quickly these changes should be implemented. Fortunately, among personality psychologists, there seems to be a bit more consensus than there is in other areas of psychology. There appears to be general agreement not only about the existence of the problem, but also about the steps we should take to improve things. This makes it somewhat easier for an editor of a personality journal to implement policy changes than it might be in some other areas, which is why JRP has been able to quickly respond to the replicability debate with concrete policy changes.
Of course, just because personality psychologists recognize that a problem exists and can agree in general about the path forward, this does not mean that we are actually succeeding in improving our practices. We may all agree in principle that replications are needed, while still failing to conduct them ourselves. We may recognize the benefits of large sample studies while still feeling the pressure to do more with limited resources. Thus, while policy changes are important, we must also evaluate the effects of those changes on the studies that we publish.
At JRP, we have primarily focused on encouraging replications and increasing focus on power and precision. Specifically, to encourage replications, we instituted a new policy that allows for authors to submit replication attempts of studies previously published in JRP (specifically, those studies published in the past five years). These papers will be subject to an abbreviated review process that focuses solely on whether the study is a reasonable (and adequately powered) replication of the original study. The rationale for the abbreviated review process (and for the decision to limit what types of replications will be considered) is that the importance of the question and the design of the study have already been evaluated and approved by reviewers, and therefore, the only question is whether the replication attempt is faithful to the original. Papers that pass this minimal threshold will be published, regardless of the outcome of the study.
The goal of this policy is to explicitly acknowledge that we value replication and to create incentives that encourage people to conduct replication studies. It is likely that replication studies will never be as highly valued as studies demonstrating a new effect, but our policy changes the risk/reward ratio in a way that favors replication. In short, when researchers chase a new finding, there is high risk involved, but also there is potentially high reward. With JRP's policy, we can lower the risk involved in conducting replications by almost guaranteeing publication when competent replication studies are conducted.
The primary concern that we heard when considering and then implementing this policy is that because replication studies would be so easy to do, the journal would be overrun with submissions from authors out to get an easy addition to their C.V. What this concern fails to recognize is that running any study—replication or otherwise—takes time and resources, and even those who value replication continue to balance their time between replication attempts and original research. Indeed, in the years since this policy has been in place, we have only received a handful of papers submitted under the replication policy. So we are far from being overrun with replications, and I hope that the numbers increase in the years to come.
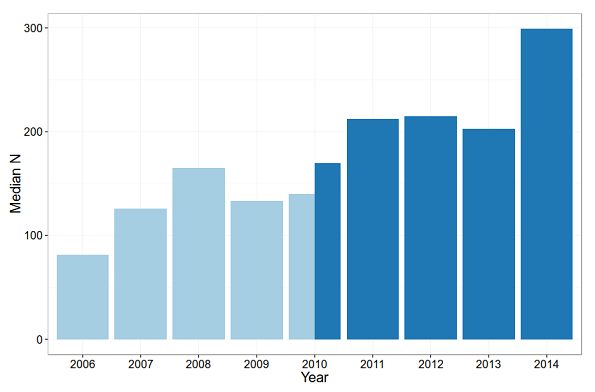
Our second major policy initiative was to require authors to explicitly justify sample sizes and to have editors take a more active role in evaluating power and precision in the early stages of the review process. Papers that are clearly underpowered are much more likely to be rejected without review as a result of this policy. Ideally, we would evaluate the effects of this policy by tracking power in our studies over time. Unfortunately, with the types of studies published at JRP, this can be a tricky thing to do in an efficient way. We have, however, begun to track some characteristics of our studies over time. Specifically, my student Carol Tweten and I borrowed the approach used by Chris Fraley and Simine Vazire in their paper assessing the "N-Pact Factor" of various journals, and started tracking the median sample size of studies published in JRP. The figure below shows how sample sizes have increased over the past nine years. The data from 2006 to 2010 (the light blue bars) come from the Fraley and Vazire paper (where they selected a sample of articles from each year); the data in the dark blue bars are based on our own analyses, where we included median sample sizes from every study we published (the discrepant values for 2010 are due to this difference in sampling strategy). As can be seen in the figure, sample sizes have increased steadily, more than tripling from 2006 to 2014. The increase from 2013 to 2014-a time when the new policies were coming into effect-was especially pronounced. Of course, we do not know whether these improvements will continue over time. Indeed, we cannot really be sure they are even improvements. It is possible that the increase in sample size has co-occurred with a decrease in the effect sizes that the studies are designed to detect. However, it is encouraging that at least this one easily tracked contributor to the power of our studies is improving over time.
One concern that has been mentioned when thinking about policies that encourage larger sample sizes is that the enforcement of such policies would make it more difficult for researchers at universities with small participant pools, or that it would make it more difficult to conduct studies that use more expensive or burdensome methods. We have also tried to examine this issue by tracking certain features of the studies that are published in JRP. For instance, we can show that as sample size has increased, there has not been an increase in studies that rely on large samples of undergraduates (if anything, there has been slight decrease in such studies). Furthermore, although the frequency of some methods appears to have declined over time, others have increased. However, it will be necessary to track this information for longer periods of time to see the long-term effects of these policies. We plan to continue gathering this information for JRP and perhaps other journals, so we can see what effect these policies really have.
In the past few years, there has been considerable debate-both in the pages of our journals and in social media-about the extent to which there is a reproducibility problem and about the things we can do to fix such a problem. Often, these debates focus on hypothetical outcomes that could potentially occur if certain reform-based policies were to be implemented. Fortunately, the extent to which policy changes lead to positive or negative outcomes is an empirical question. At JRP we have not only implemented new policies we think will have the biggest impact on the quality of the science we publish, we have also attempted to track the effects of these policies over time. Hopefully, by doing this, we can contribute to knowledge not only about personality psychology, but also about best practices for ensuring that high quality research makes it into the pages of the journals in our field.